Financial Fraud Analysis and Detection
(Python, Scikit-learn, Pandas, Imbalanced-learn)
Description
- Conducted exploratory data analysis (EDA) on financial datasets, implementing data cleaning techniques and detecting outliers.
- Employed feature selection methods such as Information Gain and Correlational Analysis to identify relevant features.
- Utilized unsupervised algorithms including Isolation Forest and Local Outlier Factor for detecting anomalies within the data.
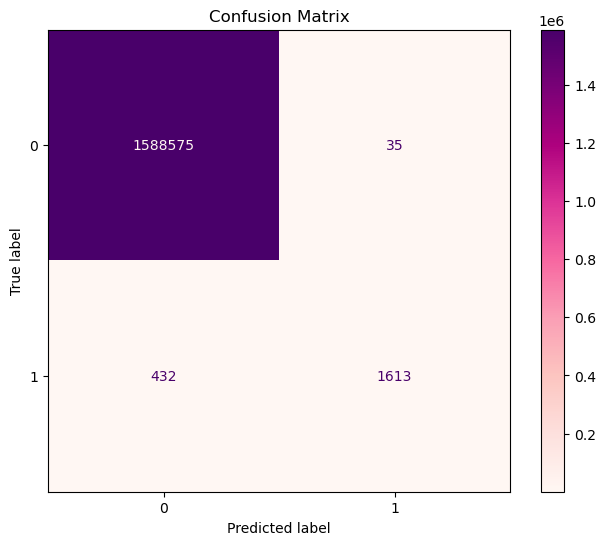
- Implemented a Random Forest classifier specifically tailored for the detection of financial fraud.
- Addressed data imbalance issues using Synthetic Minority Over-sampling Technique (SMOTE) and evaluated its impact on model performance compared to non-balanced datasets.
Results
Additional Information
The dataset is used from kaggle. The link to the notebook Link