Kaggle-Playground-Series-2024-Loan-Approval-Prediction
(Python, Numpy, Matplotlib, Seaborn, Scikit-learn, Pandas, Imbalanced-learn)
Description
- Developed a predictive model to determine the likelihood of an applicant’s loan approval, enhancing classification modeling skills.
- Performed data preprocessing, including loading, merging, checking for duplicates, and handling missing values (NaNs).
- Conducted Exploratory Data Analysis (EDA) through visualizations and statistical analysis to explore feature distributions and relationships.
- Engineered features by creating new variables, transforming features, and optimizing data representation for improved model performance.
- Experimented with multiple classification algorithms, such as: ExtraTrees, XGBoost, Random Forest, Gradient Boosting, CatBoost, LightGBM.
- Identified the best-performing model using stratified cross-validation scores and fine-tuned hyperparameters for optimal performance.
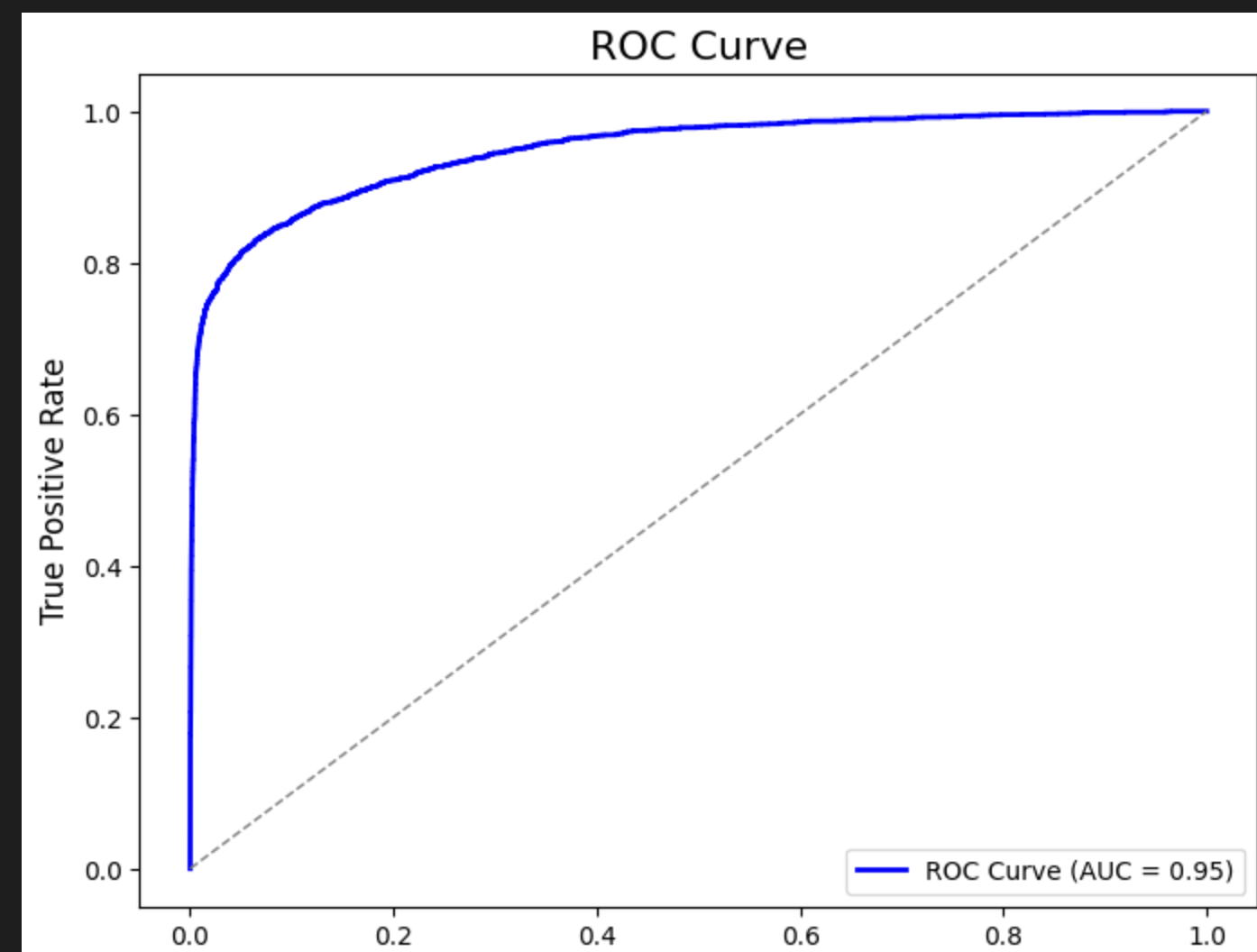
- Optimized model evaluation with metrics like F1-score, precision, recall, and ROC curves, and assessed predictive capabilities across various probability thresholds.
- Addressed data imbalance issues using Random Over-sampling Technique and evaluated its impact on model performance compared to non-balanced datasets.
- Employed model blending and stacking by combining top classifiers using weighted voting classifiers and logistic regression as a final estimator.
- Achieved a final AUC score of 0.96 on Kaggle’s test set, demonstrating strong proficiency in machine learning workflows, from data preprocessing to model deployment.
Results
Additional Information
The link to the Kaggle Competition Link
The dataset is used from kaggle. The link to the notebook Link