Instrumar's Pipeline for Manufacturing Fault Classification
Objective
The objective of this project is to develop and evaluate Active Learning (AL) techniques to improve fault classification in Industrial fiber manufacturing, specifically targeting the challenges of labeling large quantities of time-series sensor data. By focusing on informative samples, the project aims to reduce the labeling effort and costs while maintaining or improving classification performance. Additionally, a novel class-balancing instance selection algorithm is introduced to address the class imbalance problem, ensuring that less-represented fault classes are adequately labeled for training, thereby enhancing the robustness and efficiency of the fault detection system in dynamic manufacturing environments.
Description
- Developed Instrumar’s Active Learning Pipeline for fault classification in industrial manufacturing processes.
- Automating the identification and classification of production faults
- Applied SPC based anomaly anomaly detection techniques for identifying real-life manufacturing faults that needs to be classified.
- Performed domain specific feature generation, selection, and dimensionality reduction methods.
- Developed a novel class balancing instance selection algorithm to address data imbalance challenges inherent in Instrumar’s time series data, ensuring robust and accurate fault classification.
- Implemented multiple active learning strategies to intelligently select the most informative data samples for annotation, optimizing the training process and reducing annotation cost and time.
- Integrated state-of-the-art machine learning models including XGBoost, GradientBoosting Classifier, and Neural Networks to leverage the power of advanced algorithms for fault classification.
- Achieved significant improvements in fault classification efficiency, contributing to enhanced operational performance and cost savings for Instrumar.
Results
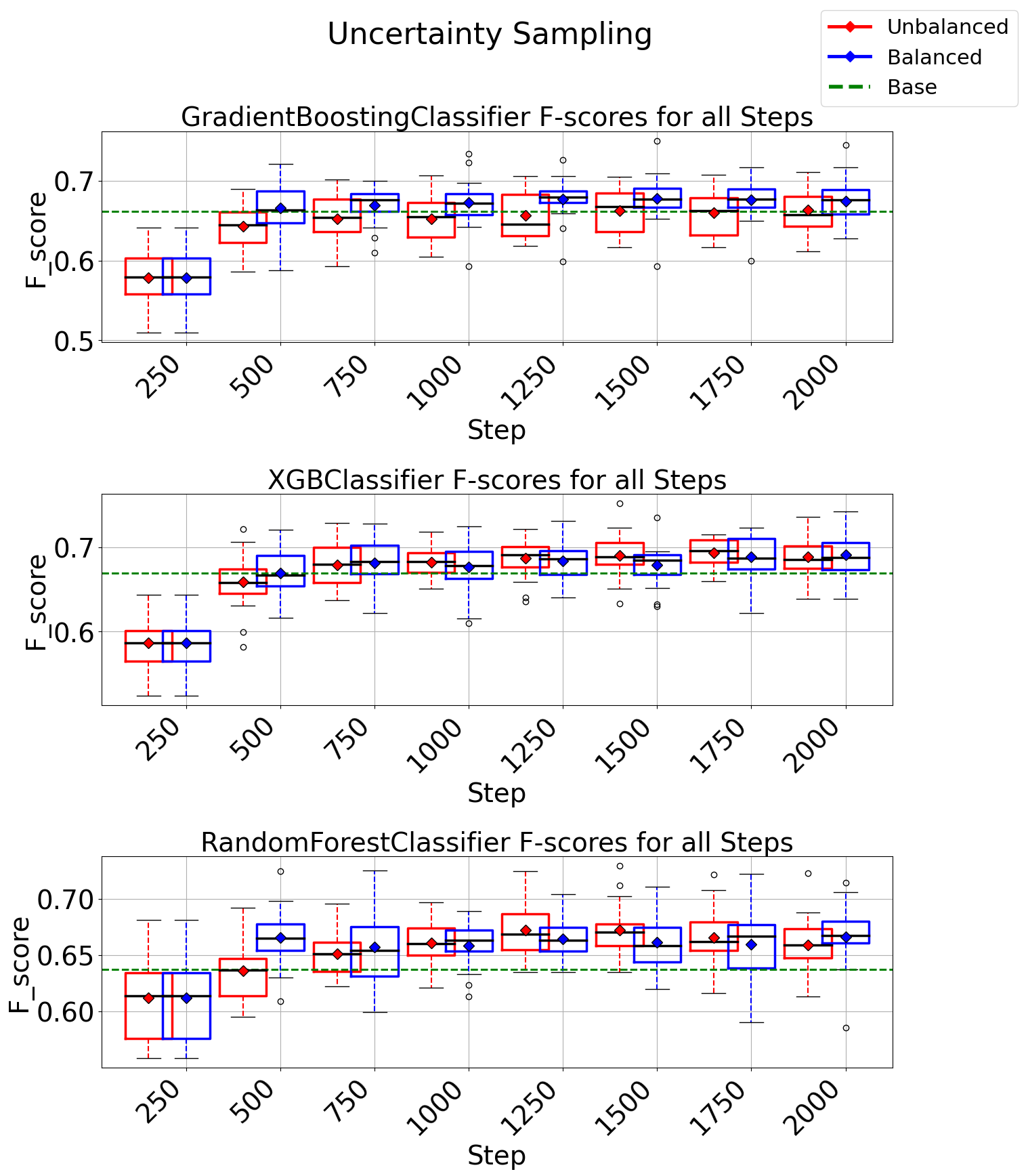
- Reduced Labeling Effort: Achieved a 5x reduction in the amount of labeled data required for accurate fault classification compared to conventional supervised machine learning techniques on Instrumar’s data.
- Addressed Class Imbalance: Successfully integrated the class-balancing instance selection algorithm, improving the selection of underrepresented classes and mitigating bias in fault classification which is very evident in real-life timeseries.
- Enhanced Performance: The pipeline demonstrated efficient and accurate fault classification with a significant reduction in data labeling costs and time for Instrumar.
- Improved Fault Detection: The proposed solution proved to be effective for dynamic and diverse manufacturing environments, showing promise for real-world industrial applications.
Additional Information
The above work has been accepted for publication in IEEE Systems Conference 2024. Link